Quantum SLI , com bridges 


")




 IBM Power5 MCM:
IBM Power5 MCM:

Um Vídeo com 1.6 milhões de views de alguém a comprar processadores retail antigos a um preço mais baixo no Ebay. Fantástico.Descobri este tópico e lembrei me deste vídeo do Linus. Supostamente são processadores i9 Extreme Edition, com PVP de 2000$ e comprou 3 por 1000$. Serão verdadeiros? Ou scam?




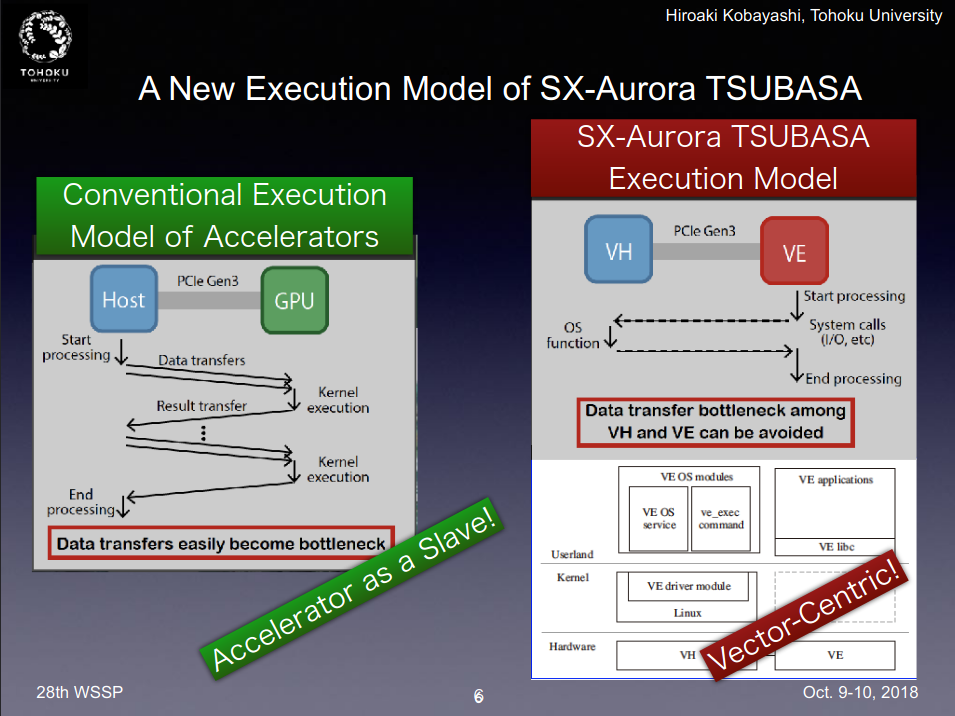
The era of vector supercomputing might sound like ancient history to some but it’s still deeply rooted in major commercial and government institutions.
The U.S. Naval Research Laboratory is among organizations hoping to salvage long-used vector codes on modern systems without high-overhead code refactoring. Specifically, they’ve looked at a deeply legacy computational fluid dynamics (CFD) solver created at the U.S. Air Force research hub, which was written in Fortran and has been added to over the years via Fortran 90 and MPI tweaks.
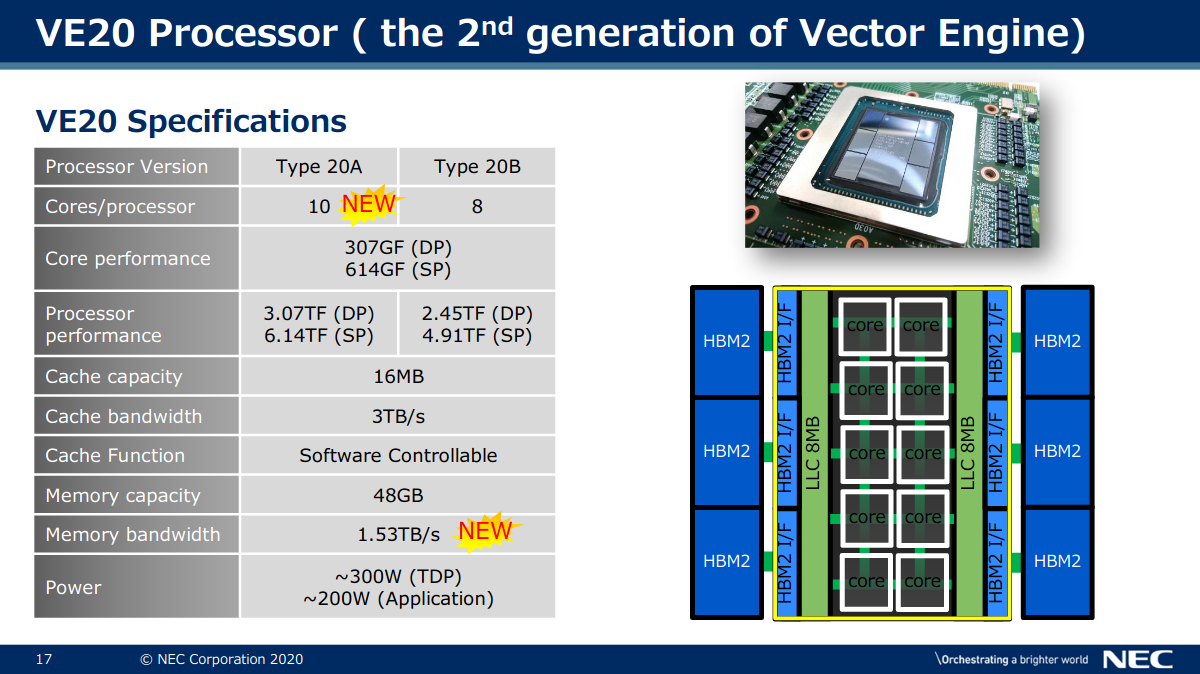
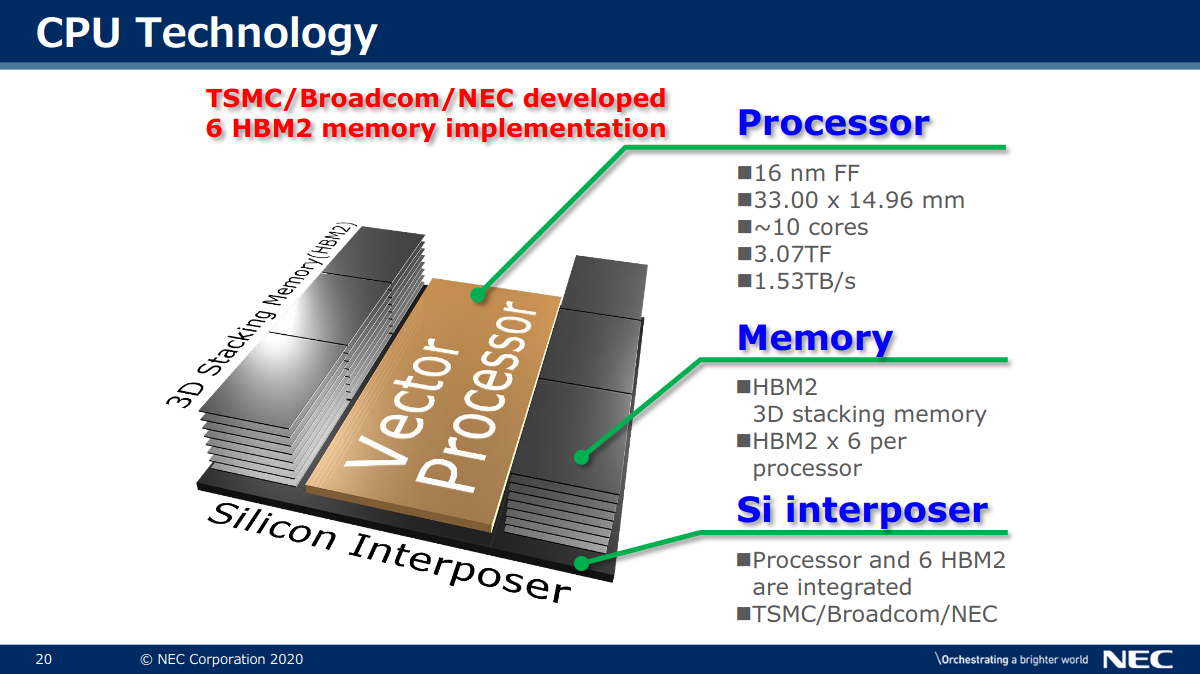
https://www.nextplatform.com/2021/06/22/u-s-military-looks-to-nec-to-salvage-way-legacy-codes/NEC’s vector history goes all the way back to 1983, just as some of the codes still used today do but they’ve managed to scale compute capability in the NEC Vector Engine in way most modern. Each Vector Engine has 8 total cores for a combined 2.15 teraflops of double-precision performance with all you might expect from other leading processors (six HBM memory modules/48GB, for instance). The secret sauce is in NEC’s scalar processing unit, which takes in all the non-vector instructions on each code while the vectorized C, C++, and Fortran with MPI run on the VE. These units are scalable with each host handling up to 8 VE machines (in the case of the Naval Research Lab these were housed in an HPE Apollo 6500 Gen 10 8 VE system).









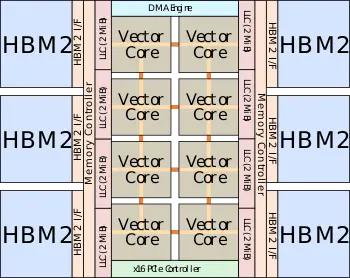
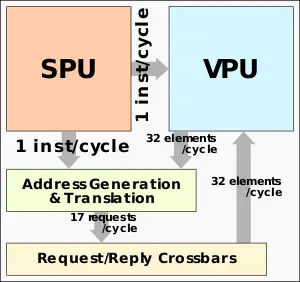
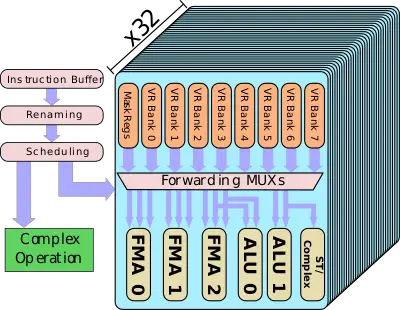
Each VPU now has 32 VPPs - all identical.
The VPP is designed such that all three FMAs can execute each cycle – each one can be independently operated by a different vector instruction. Every FMA unit is 64-bit wide and can support narrower packed operation such as 32-bit for double the peak theoretical performance.
https://en.wikichip.org/wiki/nec/microarchitectures/sx-auroraThe peak theoretical performance that can be achieved is 3 FMAs per VPP per cycle. With 32 VPPs per VPU, there are a total of 96 FMAs/cycle for a total of 192 DP FLOPs/cycle. With a peak frequency of 1.6 GHz for the SX-Aurora Tsubasa vector processor, each VPU has a peak performance of 307.2 gigaFLOPS. Each FMA can perform operations on packed data types. That is, the single-precision floating-point is doubled through the packing of 2 32-bit elements for a peak performance of 614.4 gigaFLOPS.
 :
:









 ):
):

The lab has a number of systems from AI chip upstarts, including Cerebras (CS-1 system), a Graphcore machine, and a SambaNova appliance. The list will be extended with Groq hardware coming online soon, along with other devices over the course of the next year or two.
One of the goals of Argonne’s stretch across the AI startup ecosystem is to understand where more general purpose GPU-accelerated HPC might be better served by more AI-specific hardware—not to mention how these systems mesh with Argonne’s existing fleet of supercomputers.
Prasanna Balaprakash, computer scientist at Argonne National Lab says that when it comes to “noisy” projects with this surrogate-level role in larger HPC applications, the SambaNova system has performed well with some clear advantages over GPUs in terms of data movement and avoiding context switching.
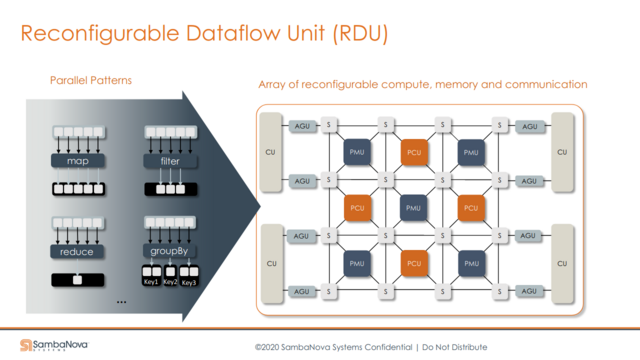
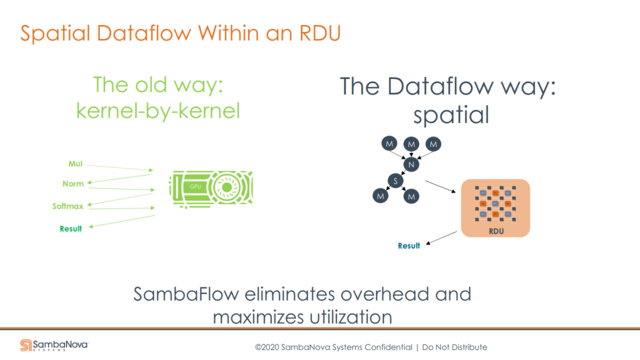
“SambaNova addresses these two issues via their DataFlow execution mechanism. The data from memory enters into the PMU (memory) and the PCU (compute) units. The convolutions are pooling are mapped onto these and the data flows from convolution to pooling without going back into main memory.”

“By the time we’ve moved into the second convolution, the other data sample required for the first one can be pipelined and staged and operating at the convolution one layer. That means there’s no data movement from the PMUs to the PCUs to main memory and context switching doesn’t need to happen as much as it would with a GPU.”
https://www.nextplatform.com/2021/07/06/argonne-cuts-through-the-noise-with-sambanova-system/Another area of interest for Balaprakash is doing forecasting across very large graphs, which would have to be heavily segmented to fit onto GPU memory.



This material is based on research sponsored by Air Force Research laboratory (AFRL) and the Defense AdvancedResearch Agency (DARPA) under agreement number FA8650-18-2-7865.
https://apps.dtic.mil/sti/pdfs/AD1092828.pdfABSTRACT
We have developed hardware and software for a universal data analytics accelerator called Plasticine. Plasticine hardware is basedon the novel concept of a reconfigurable dataflow architecture (RDA) which has both reconfigurable memories and reconfigurablecompute. RDAs provide high energy efficiency without sacrificing programmability. We have fabricated a 7nm chip implementationof Plasticine I that provides significant performance and energy improvements compared to GPUs and FPGAs. Architecture studiesfor Plasticine II include support for dynamic on-chip networks, sparse-matrix computations and graph analytics. Plasticine softwareincludes high-level and low-level compilers for converting TensorFlow machine learning applications into optimized configurationsfor Plasticine.
Jon Peddie has put together short overviews of graphics chips that have made a major impact over the years. It is a fun look back at how we got to where GPGPUs are the norm.
Volume 1 (Download Volume 1 as a .PDF)
https://www.electronicdesign.com/graphics-chip-chronicles


https://www.hardwaretimes.com/meet-...pu-2ghz-designed-in-russia-on-a-16nm-process/It supports eight channels of DDR4-3200 ECC RAM and 32 PCIe 3.0 lanes along with four SATA III channels. It’s networking capabilities include 10 Gbit and 2.5 Gbit Ethernet controllers. The processor is based on a 16nm process node and is the first chip in the Elbrus family with support for virtualization and a peak operating frequency of 2GHz.
The Elbrus-16S packs a decent 12 billion transistors, with a rated performance of 1.5 TFLOPs FP32 and 750 GFLOPs FP64. The chip is designed for multi-socket systems with up to four nodes and memory support of up to 16TB.

https://www.hpcwire.com/off-the-wir...processing-performance-in-stac-a2-benchmarks/STAC-A2 Benchmark tests, which measure the computational performance of Monte Carlo-based risk simulations common in financial markets. An independent audit conducted in April 2021 by the Securities Technology Analysis Center (STAC) showed that in cold runs of a workload that calculates options Greeks for a large problem size, this solution had the fastest time of any system STAC has publicly reported to date.







