U.S. Blacklists Two Major Chinese CPU Developers
The U.S. Commerce Department has
added seven Chinese entities to the DoC's Entity List, essentially barring these companies and organizations from obtaining almost all advanced technologies developed in the U.S. Among the entities are two major CPU developers from China: Tianjin Phytium Information Technology and Sunway Microelectronics (or Shenwei Microelectronics).
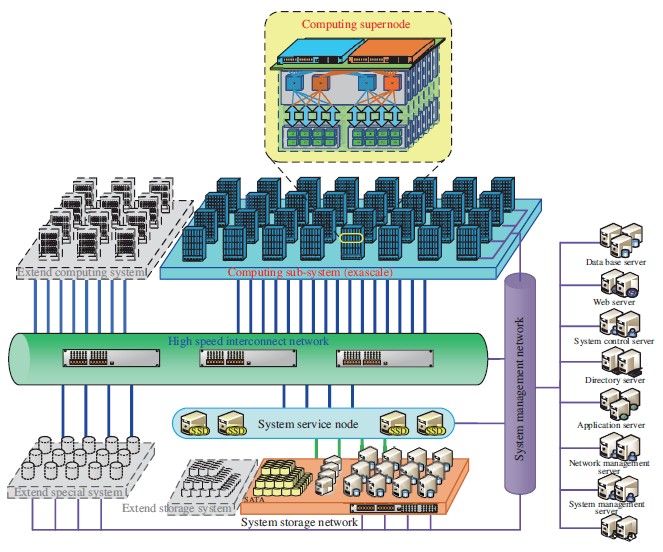
The Department of Commerce’s Bureau of Industry and Security (BIS) believes that the newly added seven entities supported modernization of the Chinese People Liberation Army by producing supercomputers used for military purposes, development of new weapons of mass destruction as well as other destabilizing efforts. In particular, BIS blacklisted four supercomputer sites in China, including the National Supercomputing Center Jinan, the National Supercomputing Center Shenzhen, the National Supercomputing Center Wuxi, and the National Supercomputing Center Zhengzhou.
Also, the blacklist now includes CPU designer
Tianjin Phytium Information Technology, which develops system-on-chips for client and server PCs based on the Armv8 ISA, and
Sunway Microelectronics, which as a part of Shanghai High-Performance Integrated Circuit Design Center, designs proprietary supercomputer processors.
The inclusion of an entity into the Entity List restricts its ability to access items and technologies that are parts of the U.S. Export Administration Regulations (EAR). American companies cannot export, re-export, or transfer items subject to the EAR to entities in the Entity List without a special license, which will be subject to a presumption of denial.
CPUs and SoCs, including those for supercomputers, are designed using electronic design automation (EDA) as well as other tools and technologies developed in the U.S. Without access to these tools and technologies, it will be close to impossible for Phytium or Sunway to develop their processors. It is unclear whether contract makers of semiconductor like TSMC or SMIC can actually produce chips for Phytium and Sunway.
"I have not in my decade in China met a chip design company that isn’t using either Synopsys or Cadence," said Stewart Randall, a consultant in Shanghai who sells electronic design automation software to top Chinese chipmakers in a conversation with
The Washington Post.
Many supercomputer centers in China nowadays use CPUs and SoCs developed in the country, but they still use certain technologies designed in the U.S. From now on, those who want to sell the aforementioned four supercomputer centers in China something made or developed in the U.S. will have to apply for an appropriate license.
"Supercomputing capabilities are vital for the development of many – perhaps almost all – modern weapons and national security systems, such as nuclear weapons and hypersonic weapons," said U.S. Secretary of Commerce Gina M. Raimondo in a statement. "The Department of Commerce will use the full extent of its authorities to prevent China from leveraging U.S. technologies to support these destabilizing military modernization efforts."
Previously the DoC blacklisted Huawei Technologies and its chip design arm HiSilicon as well as contract maker of chips SMIC on the same grounds of supporting Chinese military efforts.