Nemesis11
Power Member
Breaking down Intel’s upcoming Xeon Phi Knights series HPC platform.
Who would have thought that just a few years ago that the troubled Larrabee platform, which cost quite a few high level Intel executives dearly, would have been re-born so successfully within the high-performance computing (HPC) field as Xeon Phi? After all, Nvidia, and, with much lesser success, AMD, have already tried the GPGPU accelerator approach there, and real-world limitations of the heterogeneous computing software model issues led to less deployable apps than originally thought.
Intel did, and still does, have one huge comparative advantage in this situation: its broad x86 code compatibility. To put it simply, this allows inline programming from the same code base as usual Xeons which shortens the software optimized porting time from months to days, with associated costs savings. This was one off the reason why its first commercial Knights Corner model, precisely, 48,000 of them, found their way into Guangzhou’s Tianhe 2, the world’s fastest supercomputer. That machine will be expanded to its full 100 Peta flop (PFLOPS) original target capacity over the next year or so. NASA’s new supercomputer and a number of other large systems incorporate the Xeon Phi as well.
So, it is expected Intel would continue to nurture the new baby, and, in mid-2015, Knights Landing, the next generation Xeon Phi, is on the cards – with lots of changes.

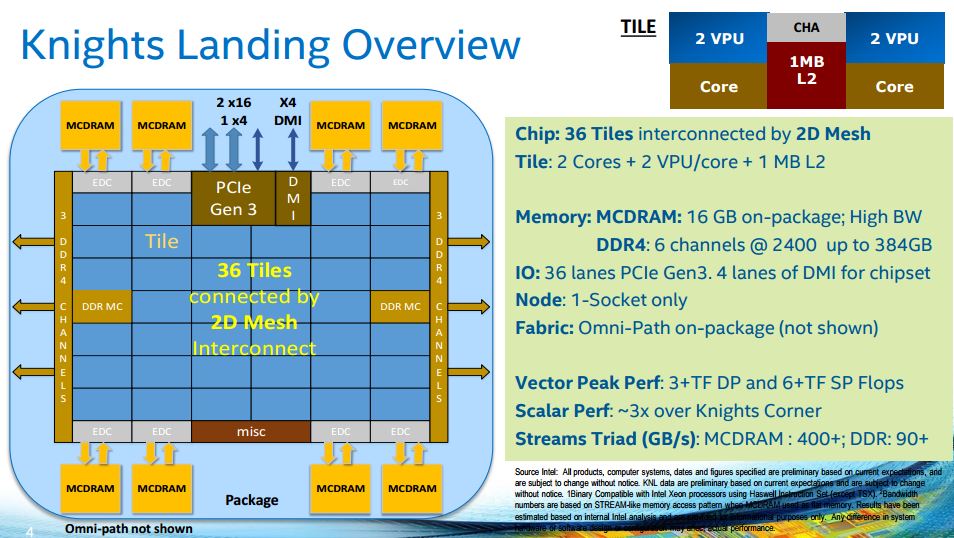
Quite simply, Knights Landing is a standalone CPU, just like any Xeon or Core Intel processor. It can boot the OS, connect to I/O bridges, have a direct HPC interconnect link to other Knights Landing and Xeon processors (Intel’s 100 Gbps Cray interconnect) and use the expandable main memory just like usual processors.
Each Knights Landing Xeon Phi has a 6-channel DDR4-2400 memory controller supporting up to 384 GB RAM per socket, a big improvement over the 16 GB seen in the current Xeon Phi. What about losing the GDDR5 bandwidth benefit, though? Well, there’s a bunch, up to 16 GB, of directly attached stacked 3D memory on top of the Knights Corner package at 500 GB/s bandwidth (over 50 percent faster), and with lower expected latency, than the top memory bandwidth of Tesla K40 or AMD R9-290X today.

This memory can act either as a cache to the main RAM, or simply as the first 16 GB of the memory address space, whatever the specific environment prefers. Alternatively, you can design 4 GB of it as a cache and the remainder as the directly addressable memory.
There are also 36 PCIe v3 lanes for HPC interconnects, external GPU or local extra Knights Landing co-processor card connection, I/O bridges, SSD and so on.
The 72-core Knights Landing will use modified Atom Silvermont cores as the front end to the 512-bit wide vector units supporting AVX-512 instruction set. Silvermont, proven now in the mobile and microserver arena, has around twice the average efficiency of the old, 1997 Pentium-style in-order cores used in the first Xeon Phi.

Knighs Landing promises over twice the performance of the current models: 6 TFLOPs single precision FP and, more importantly, 3 TFLOPs double precision FP per socket – the latter one counts more for productivity technical computing. Remember, AMD was cutting the DP FP rate in the R9 290 and 290X to 1/8 of SP compared to 1/4 of SP in the HD7970 to avoid competing with the future HPC accelerator flavor of R9-290X?
At over 3 TFLOPs per socket, and four sockets easily per each 1U in a rack, you could have half a petaflop in a usual 42U rack without using any special dense system packaging approaches. If relying on super dense, liquid cooled designs like Eurotech, fitted within a larger rack, a petaflop rack becomes possible on the X86 platform for the first time in 2015.
Now comes the icing on the cake. A quarter later, there will be a special packaging flavour, called Knights Landing-F, that will use Intel’s recently acquired and further developed low latency Cray HPC interconnect controllers, at 100 Gbit/s across two channels, connected via 32 of its PCIe v3 lanes, directly on top of the package with optical links coming out from there to the backplane switch.
It will help save a tiny bit of latency and some power too, but the unique approach of supercomputer interconnect links coming out directly from the CPU chip package towards thousands of other same CPUs (or Broadwell Xeon E5 v4 as well) is a breath of fresh air.

Finally, towards the end of 2015, Knights Landing will still be also available as a PCIe co-processor card to the usual Xeon systems, although Intel’s card design only uses 2 out of 6 DDR4 channels for up to 64 GB RAM.
For the first time there would be an opportunity for third party OEMs to design improved Knights Landing cards with more RAM? Either way, it seems Intel prefers to offer the future Xeon Phi as stand-alone processors.
HPC is serious business
Intel is dead serious about capturing the dominant position in HPC accelerator market with the future iterations of Xeon Phi, and, even more importantly, creating Xeon Phi-only SIMD supercomputers for the first time, with petaflop-a-rack performance.
The usual serial and scalar jobs will still run better on ~1 TFLOPs 16-core Broadwell Xeon E5 v4 at the same time, but, well, at least there will be a choice of two approaches, or easy combining them into a single system with common code running on both.
Finally, aside from HPC, Knights Landing may be a ideal CPU for certain kinds of simulation-oriented heavily parallel games too. Just think of the possibilities.
http://vr-zone.com/articles/xeon-phi-knights-series-continues-landing-2015/64112.html
Então, o que temos aqui no Futuro Xeon Phi:
- Um processador completo que pode bootar um sistema operativo. Pode não funcionar como um coprocessador.
- 72 cores Atom/4 Threads por core. Parece-me que em vez de ser um ring a nível de disposição, é um mesh.
- Parece ter 1 MB L2 por cada 2 cores.
- 14 nm
- 2 unidades AVX-512 por core, compatíveis com outros cpus Intel com estas instruções, menos Transactional memory.
- 16 GB de stacked 3D Memory a 500 GB/s que podem funcionar de várias formas, como Ram ou cache.
- 6 controladores de memória que podem levar 384 GB de Ram por cpu, além da stacked Ram. DDR4-2400.
- 36 lanes Pci-Ex 3.0
- Integrated Fabric para comunicação a 100 Gbits, que ocupam 32 lanes Pci-Ex.
- Entre 160 a 215 W
- Previsão de 6 TFlops SP e 3 TFlops DP.
Parece-me interessante no mínimo. Não é nada que vá estar disponível para o consumidor, mas é uma montra de tecnologia.
Claro que visto o caminho que está a seguir a Intel, a nVidia não tem outra hipotese se não criar Teslas com processadores Arm integrados, para não precisarem de um cpu x86 agregado.
São tempos interessantes que aí vêm.
Última edição:







")