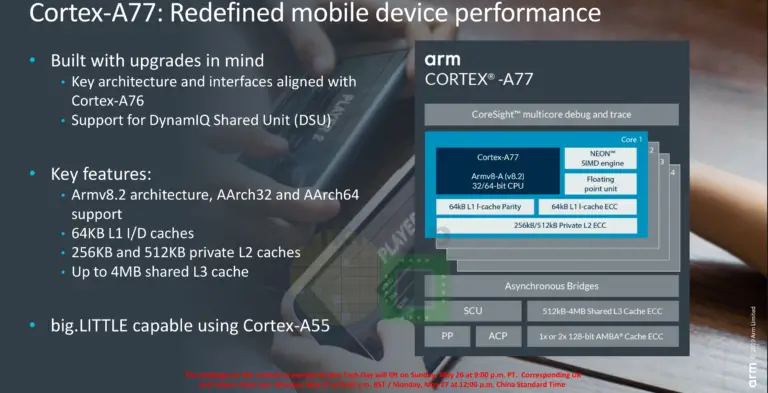
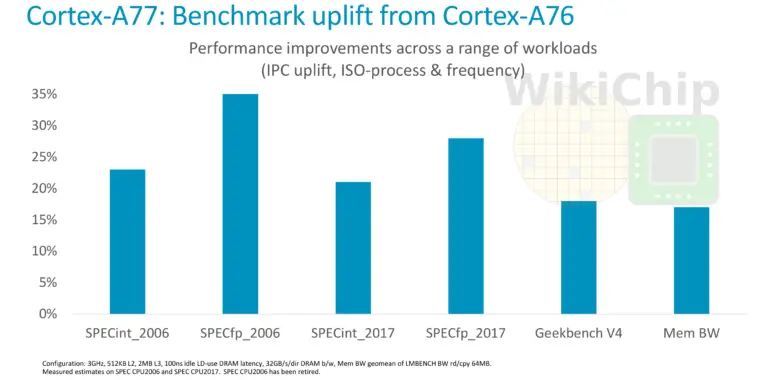
Apenas um ano depois do A-76 a ARM anuncia o A-77, que tem evoluções maiores que seria de esperar.
Microarchitectural enhancements
agora vou usar os bonecos do gajo do Wikichip que é mais fácil
Front-end improvements
Back-end improvements
Execution units
Memory subsystem
https://fuse.wikichip.org/news/2339/arm-unveils-cortex-a77-emphasizes-single-thread-performance/
Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
https://www.anandtech.com/show/14384/arm-announces-cortexa77-cpu-ip
Microarchitectural enhancements
agora vou usar os bonecos do gajo do Wikichip que é mais fácil
Front-end improvements
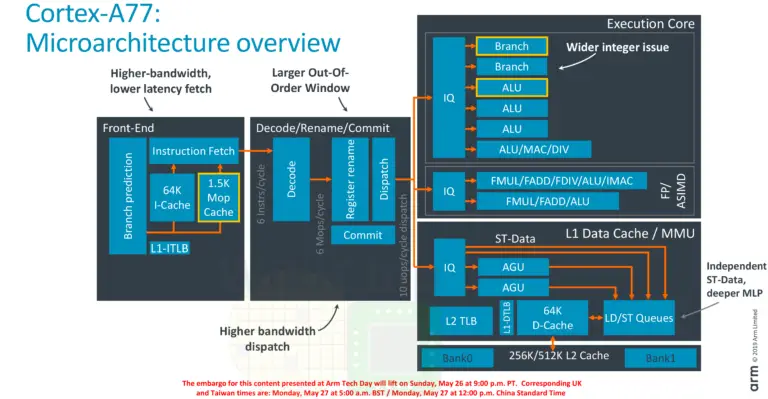
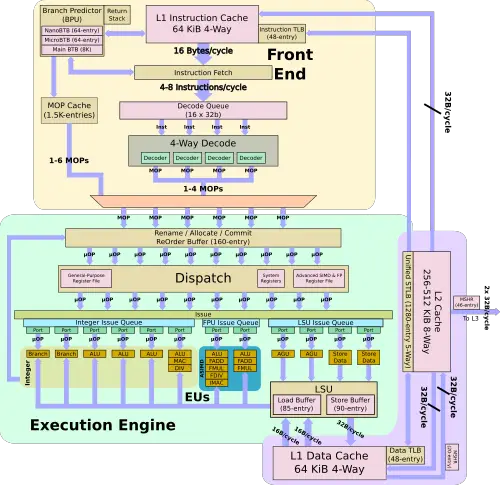
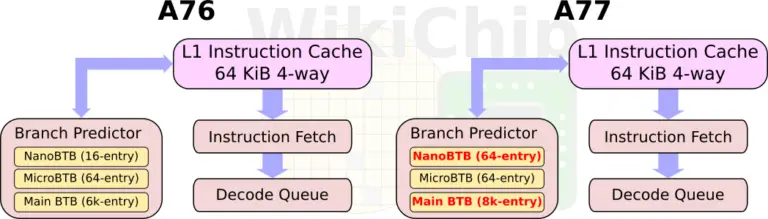
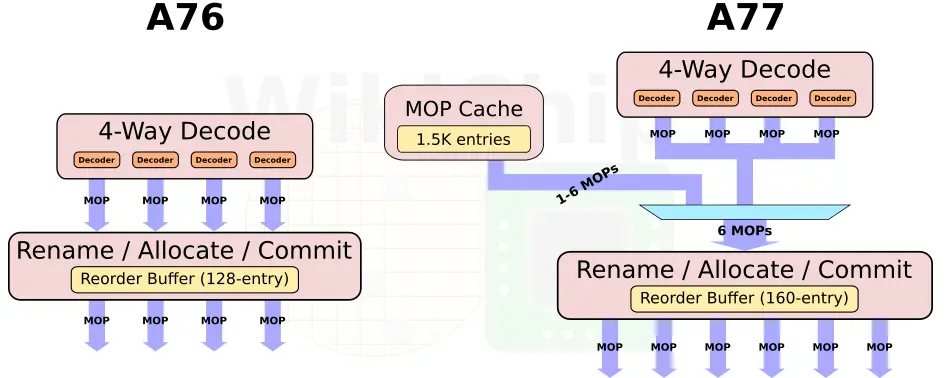
In the A77, Arm enhanced the front-end in order to improve the instruction delivery bandwidth. The improvements come from three sources – an improved branch predictor, a deeper runahead window, and a new MOP cache. Like the A76, there is a branch prediction unit decoupled from the instruction fetch.
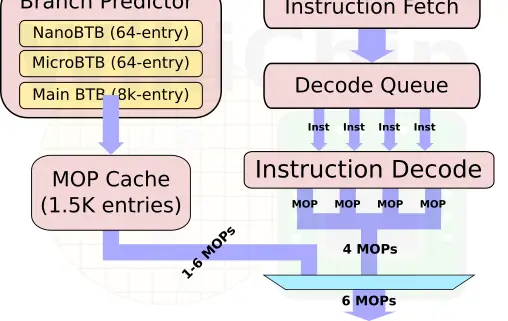
One of the other major additions to the front-end is the new macro-operation cache. This L0 decoded instruction cache is 1.5K-entries deep and has a hit rate often exceeding 85% in real workloads. This is very similar to the kind of benefits that Intel reported when they first added the µOP cache in Sandy Bridge
Back-end improvements
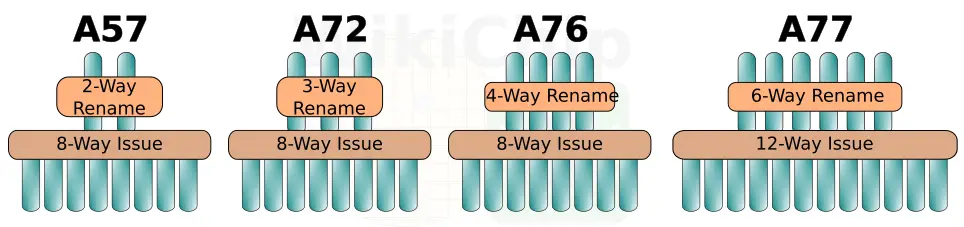
Historically, Arm has been somewhat conservative in how much they widen the pipeline. In some designs, they even narrowed the pipeline to achieve better power-performance-area efficiency. With the A77, Arm pulled out all the stops in order to increase the IPC. Arm increased the width of the pipeline by 50% with up to 6 instructions getting decoded, renamed, and go to dispatch each cycle. Arm only moved to a 4-way decode on their A76 last year so this is a very large change architecturally year-over-year.
The out of order window size for all recent Arm microarchitectures going back all the way to the Cortex-A57 remained the same at 128 micro-ops in-flight. Arm has always argued that the return for enlarging this was very small. On the A77, in order to expose more parallelism, the reorder buffer has also been increased by 25% to 160 instructions in-flight. This translates to roughly a 2.5-3% performance improvement at the cost of a 25% larger OoO window.
Execution units
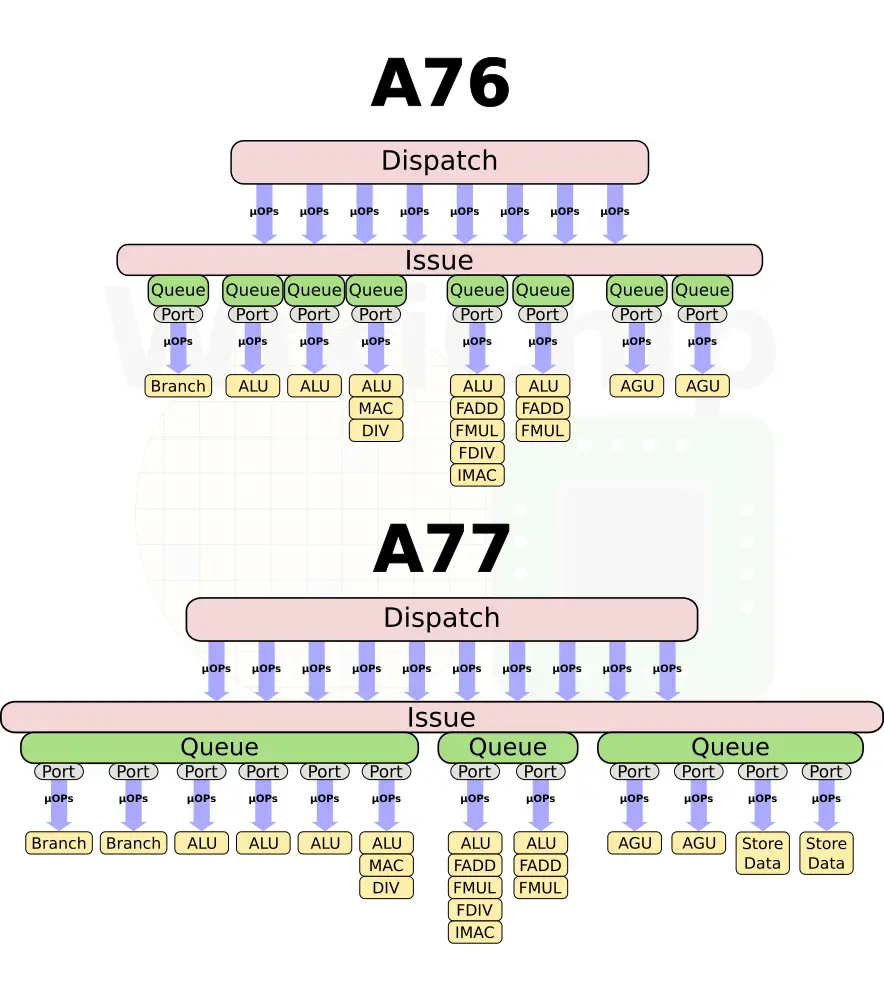
he execution units saw a number of architectural changes as well. Firstly, whereas previously there were dedicated issue queues per pipeline, on the A77, the issue queues are now unified for better efficiency. We now have one unified IQ for the integer pipelines, one for the ASIMD, and one for the memory subsystem.
The dispatch is now much wider too. Each cycle, up to 10 µOPs may be issued to the execution units. On the integer side, two new ports were added. Arm added a 4th ALU to improve integer throughput as well as a second branch unit, doubling the branch throughput. On the floating point side, Arm added a second AES unit.
Memory subsystem
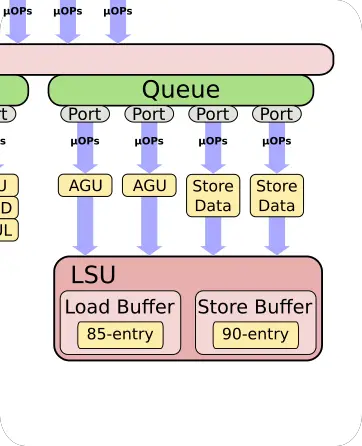
In order to cope with a wider out of order pipeline, the memory subsystem has been slightly adjusted as well. The number of in-flight loads and stores have also been increased by 25%. One of the other major changes is with the store data ports. Previously those two pipelines were shared with ALUs. On the A77 there are now dedicated store data ports.
https://fuse.wikichip.org/news/2339/arm-unveils-cortex-a77-emphasizes-single-thread-performance/
Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
https://www.anandtech.com/show/14384/arm-announces-cortexa77-cpu-ip